10 December 2019 - Machine-Learning
Uber's Data Platform
Uber has one of the most advanced Machine Learning and Data Science platforms ever built. The platform is not open-source, but they have talked about it publically various times.
Uber has one of the most advanced Machine Learning and Data Science platforms ever built. While Google and Facebook have taken to focussing on new deep learning stacks such as TensorFlow or PyTorch, the Uber team has concentrated on the tooling and best-practices of building and deploying Machine Learning into real-life applications.
The platform is not open-source, but they have talked about it publically various times.
The Problem
Uber has put a heavy focus on Machine Learning, and they see it as a core competency of their business. Their strategy is to apply Machine Learning to all aspect of their business and products. Uber doesn’t rely on a single centralised data science team. Their organisation is, primarily structured like a product company with multi-disciplinary teams responsible for a product or component. That’s not to say there aren’t dedicated DS teams, but generally, they’re spread across the organisation.
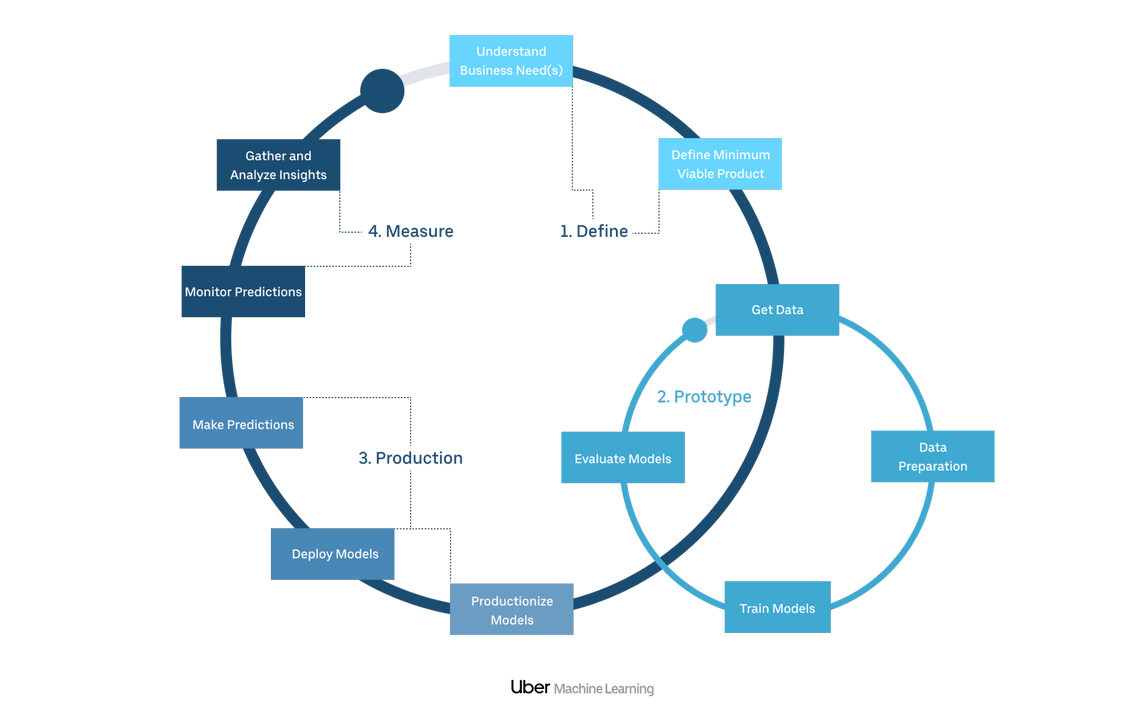
Uber identified that one of the blockers for teams deploying Machine Learning was the complex infrastructure required to run it. Teams were comfortable exploring ML on their local laptops but integrating and managing it in a production application required knowledge or skills that were not common across the business. When ML was integrated into production applications, it was running on single-use infrastructure, created explicitly for that model. The overhead of setting up, managing, debugging and monitoring this meant that for many teams, it wasn’t worth the investment to develop it in the first place.
Uber needed a way to democratise Machine Learning and enable these teams to deploy their models to production environments in the most efficient way possible. They wanted to allow a single engineer to be solely responsible for the model; from creation to production operations. They understood that the faster this individual could cycle through the process, the better the overall output. They focussed very heavily on the developer experience required to encourage the fastest possible cycle times.
Solution
Companies such as Facebook and Google have focussed their research on building new Deep Learning frameworks; such as TensorFlow and PyTorch. Uber has invested heavily in the; process, tools and technology required to deploy Machine Learning into production with the least possible friction.
They deployed their initial version of the platform in 2015, initial versions focussed on simply enabling an end-to-end workflow. More recent versions have concentrated on improving the developer experience. As the platform has matured, new services and products have been added. Today several components make up the overall platform.
The heart of the Uber platform is a tool named Michelangelo, a “ML-as-a-Service” platform. Michelangelo automates parts of the model lifecycle enabling different teams to build, deploy and monitor ML models at full scale.

Technology-wise Michelangelo uses a sophisticated, modern stack; HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow.
Managing the data - “The most complex part”. The platform has to provide accurate data and enable quick access for prototyping. It must also ensure data consistency for model retraining in the future. Once deployed, the platform must ensure that the model gets the exact same data used when trained.
Most production designs require models to be real-time with a request-response type interaction initiated via an API. Hadoop is used for storing historical data; each API request starts a complex data pipeline to query the data from Hadoop and wrangle it into the same format used to train the model.
Part of the Michelangelo platform includes a feature store where users can register, discover and share features. This feature store not only enables collaboration (and reuse of feature pipelines) but also provides statistical analysis of each feature over time. The feature store stores batch or real-time features;
- For batch features (such as; the average meal-prep time for each restaurant over the last 2-weeks) the data isn’t needed real-time so it can be set up as a daily/weekly pipeline job running the required Spark or SQL queries.
- For real-time features (such as; how busy is the restaurant right now) there is a separate path that allows a (Flink) job to run aggregations over the (Kafka) streaming data and write outputs into the feature store. Because the Flink aggregations are real-time, we know how busy the restaurant is right now, but we don’t know how busy it was last night or four weeks ago, this causes issues when we want to train a new model on historical data in the future. To overcome this; Michelangelo double writes the outcomes into the feature store (for real-time access) and Hive (for historical analysis in the future). It is essential to ensure parity between the real-time and historical data.
Training Models - Training is a very iterative process. The platform allows users to run a model-model comparison and evaluate different models quickly. Uber has built a forked Jupyter Lab environment, called Data Science Workbench (DSW), that they use for training models. It runs on a CPU + GPU cluster for efficient training of different types of models and provides some useful features;
- Project structure - DSW is built around the idea of a project. Each project is a folder containing multiple notebooks with multiple models, additional data, dashboards, model comparison, production performance logs, previous versions etc
- Job Scheduler - Allows scheduling of jobs for the project, such as batch feature and model retraining pipelines to be automated
- Custom dashboards - Allows Bokeh server or RShiny dashboards to be created and published for a project showing changes over time
- Model comparison - There maybe ten to one-hundred models developed during a project. Selecting a final model requires these candidates to be compared and contrasted. When a model is registered within a project, the DSW stores metadata describing the model and a visualisation tool that enables rapid comparisons. The metadata stored includes; who trained it, when it was trained, the data used to train it, the learnt parameters, the training and cross-validation set performance, model type (e.g. linear regression, boosted decision tree) etc. Publications suggest Uber has built some separate libraries to enable this, but I haven’t seen visuals or specifics.
- Autotune has been recently released to the DSW platform enabling users to automatically tune the hyperparameters of their models for best performance

Deployment and serving - Once an engineer is satisfied that their model is performing adequately, they can deploy it to production. There are two types of production model;
- Batch, which generates many predictions at once, either as a one-off job or on a schedule; hourly, daily etc
Real-time, where a web service makes the model available as an API (using docker containers to deploy). For real-time models, the client (app initiating the request) sends the required feature vector to the API. The model may require additional features from the feature store that are not available within the client. Note that because of the product-alignment within the teams, there is no split-responsibility between the client sending the data (mobile app) and the prediction service that expects the data in a specified format. Michelangelo automatically versions model deployments and routes each request according to the model name and version specified by the client.
Uber is serving 1 Million tree or linear predictions a second using this architecture. If no feature store features are required, then the response is typically five milliseconds, when additional features are needed from the feature store it adds 5-20 milliseconds.
Performance monitoring - The deployed model was trained on historical data; now it’s live; it’s using real data. You could periodically query the historical data and check that your model performance is still as expected. Still, there’s a chance that the code generating your live features isn’t producing the same results as your historical queries. The solution to this is inflight monitoring of predictions. The Michelangelo platform tracks each prediction that the service makes. The user can configure the logging service also to capture the actual outcomes, enabling live performance reporting of the model in the production.
Developer flexibility - When initially released, Michelangelo only supported models built using the SparkML library. While this enabled the end-to-end workflow, it significantly limited which users could use the platform. The team have recently released their PyML library which opens up the Michelangelo platform to any python script or model. This increased flexibility allows all types of user to build and deploy machine learning models within Uber, regardless of their framework or language of choice. It comes at the cost of model performance which is not guaranteed.

PyML allows engineers to build a Docker image that surfaces any python model through the Michelangelo platform and APIs. Engineers provide the following files as part of a model definition;
- requirements.txt additional python libraries
- packages.txt additional Debian packages to install in the docker image
- setup.sh optional pre-build commands
- model.py the model contract file, a class with a predict() method that will be called by the API
- other data or files required by the model are bundled into the docker image
PyML includes a small python package for deploying these models directly from a Jupyter notebook;


Once uploaded this model is available in the DSW where it can be deployed either via the UI or via PyML;

and can be called via the PyML library from within Jupyter or via the public API;

For offline runs of the model some input data must be provided and an output must be specified. Here we select all the data from example.data, run predictions using the offline model and load the results into example.predictions table;
